DOLOS Dataset for Audio-Visual Multimodal Deception Detection
DOLOS is an online reality-TV gameshow-based deception dataset curated for Multimodal (Facial-Speech) Deception Detection research. The dataset contains a total of 1675 video clips based on 213 (141 Male and 72 Female) participants, extracted from a total of 84 TV episodes. The duration of the video clips ranges from 2-19 seconds, with a median duration of 5 seconds. The dataset is also manually annotated for non-verbal deceptive cues using the popular MUMIN coding scheme, where we particularly focus on the visual (25 facial) and vocal (5 speech) features. The non-verbal features in the MUMIN coding scheme and the distributions of video clips are shown below.
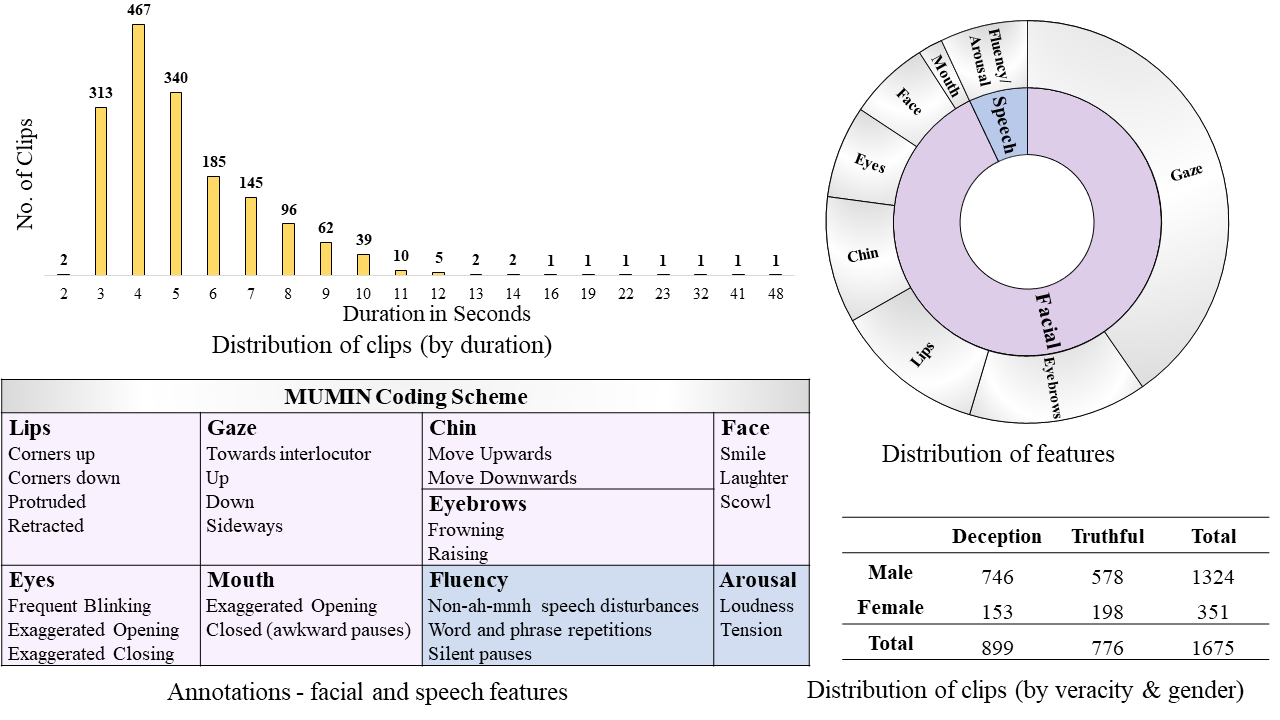
Details of the dataset contents and the accompanying code are publicly available in this GitHub repo.
Why Gameshows?
- Gameshows are a reliable source for collecting deception data because all the participants are motivated to cheat, and the ground truths are available.
- Unlike lab-based environments, gameshows have a conversational setup where the deception behaviours are more naturally presented.
Advantages of DOLOS
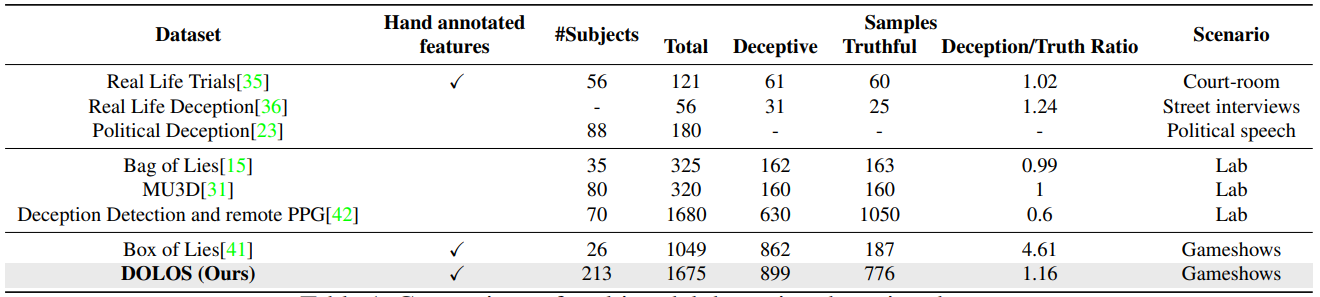
DOLOS is the largest deception dataset in terms of the number of subjects and also the largest non-lab based dataset in terms of the number of video clips. A comparison of DOLOS with other deception datasets is presented in the table below.
Terms and Conditions
- DOLOS is released for academic research only and is free to researchers from educational or research institutes for non-commercial purposes.
- The NTU ROSE Lab cannot guarantee the availability of YouTube video links for DOLOS.
- The NTU ROSE Lab does not own the copyright for the gameshow videos. Researchers will need to download the videos based on the information provide in the DOLOS download set.
- Without the expressed permission of the ROSE Lab, any of the following will be considered illegal: redistribution, derivation or generation of a new dataset from this dataset, and commercial usage of any of these datasets in any way or form, either partially or in its entirety.
- All users of DOLOS agree to indemnify, defend and hold harmless, the ROSE Lab and its officers, employees, and agents, individually and collectively, from any and all losses, expenses, and damages.
Citation
All publications based on DOLOS should cite the following paper.
Guo, X., Selvaraj, N.M., Yu, Z., Kong, A., Shen, B. and Kot, A., 2023. Audio-Visual Deception Detection: DOLOS Dataset and Parameter-Efficient Crossmodal Learning. International Conference on Computer Vision (ICCV).
If interested, please click on the “Request Annotation” hyperlink below for a copy of the Release Agreement. With your acceptance of the agreement, we will approve it and allow you to download the dataset.